Recently Ry Walker drew some ire on Twitter for arguing against coding perfectionism now that AI is writing all of our code:
Hardcore engineers, especially those not in startups, really don't like these takes.
For what it's worth I think Ry is mostly right, but not for the reasons most people who agree with him seem to cite. In 2025, it became fully clear to me that even if agents don't improve, we have a clear line of sight to an era where:
- AI will be writing effectively all code
- that code will be much higher quality (for the teams who care)
Here's a TL;DR of how we'll solve the problem of slop once and for all. Not by turning our backs to AI but instead retooling our entire process of code production and review around it.
Naive AI Coding is Pure Slop
Since we realized AI could write lots of code for cheap, we've struggled to get quality code out. The main problem has always been AI hallucinating, just at different levels of depth. At first it was hallucinating at the LOC level: writing syntactically incorrect code. As syntax became solved, it then became a problem of unidiomatic code: lots of Typescript with as any, or patterns that had fallen out of convention years ago.
And recently, the slop problem has become more subtle: AI will mostly write what it's told to do, or solve the problem as it has been prompted.
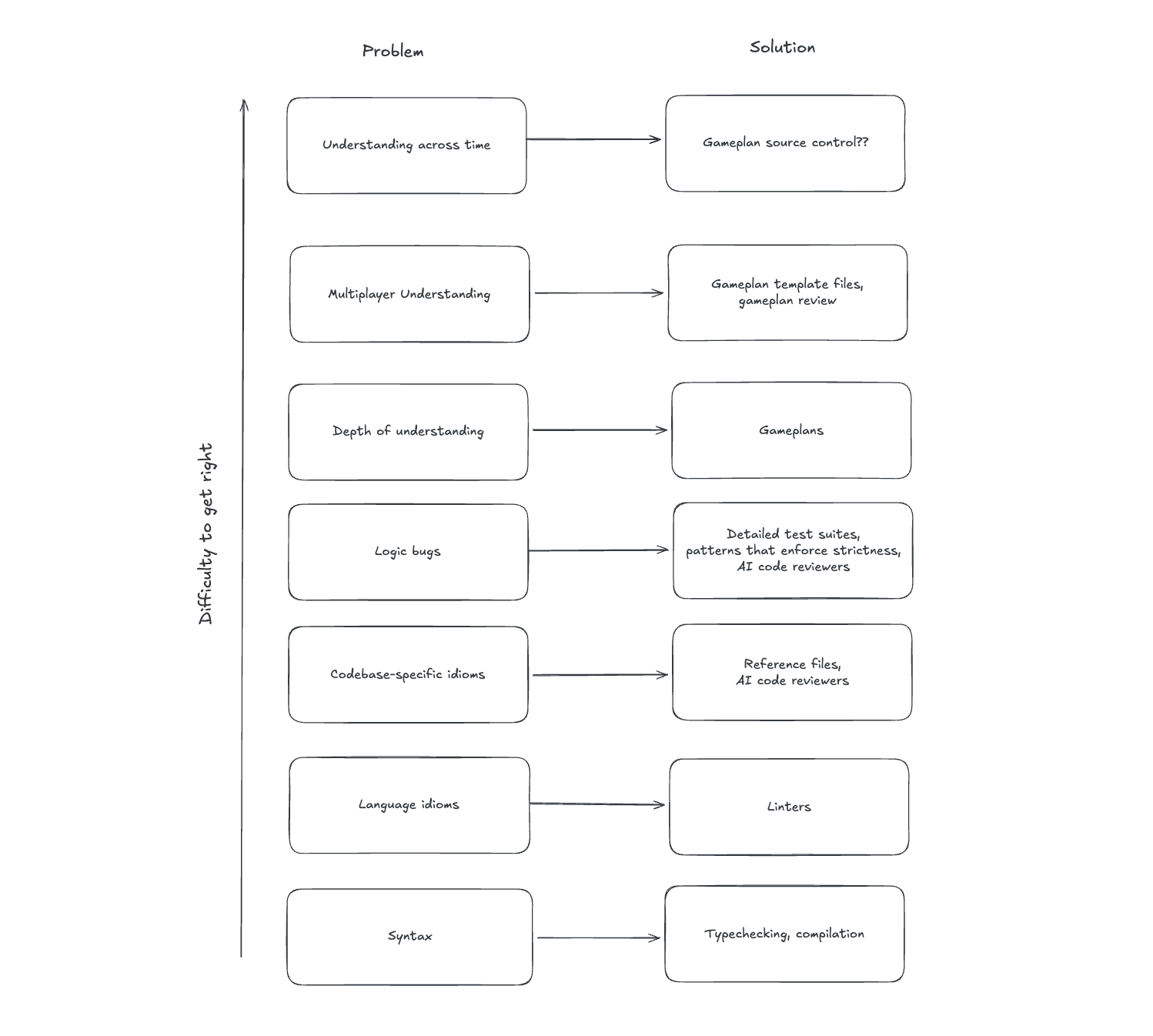
Solving the Slop Problem, Layer By Layer
AI's slop code problem isn't a monolith. Like any problem of incorrect code, it has layers. Over the last year, we've developed opinions about how to address each layer.
Layer 1: Syntax
This one's easy: types and compilation. Coding with AI would be hell if we were all still writing Javascript or untyped Python or Ruby. But compiled languages, or languages with sufficiently sound types (such as, imo, Typescript), offload a huge amount of correctness verification. If it doesn't compile or pass typecheck, you're not done yet.
Layer 2: Idioms
2.1 Language-Specific Idioms
Even if your AI-generated code compiles or passes typecheck, it can still fail to pass muster. There are countless ways to write Typescript that would never fly in production code, such as:
const foo = (someObject as any).bar // bad
For these, we can catch most problems with linters and formatters. We love biome for this. Not only is it crazy fast, you can extend it much more easily than previous generation linters thanks to its GritQL-based plugins which allow you to write custom matchers.
2.2 Codebase-specific idioms
Once a codebase reaches a certain level of maturity, patterns emerge. These patterns address codebase-specific concerns, and help standardize logic. Local patterns are great because they make it easier to review code. And when designed well, locally idiomatic code has a lower liability of maintenance than code that does the same job but veers from the pattern. But these patterns may have little precedent in the broader corpus of public code which AI coding agents are trained on. In fact, many codebase specific idioms veer away from the patterns available in public code.
At Flowglad, we learned early on how important tests were (more on that soon). But we saw quickly that coding agents were terrible at writing test suites. Namely they loved to write code like this:
vi.mock('@/db/innerHelper', () => ({
// ❌ mocks inner function used by myDatabaseMethod
someHelper: (fn: any) => fn({ transaction: {} }), // ❌ any
}))
describe('myDatabaseMethod', () => {
let organization: any // ❌ any
let product: any // ❌
let price: any // ❌
beforeEach(() => {
price = {
productId: 'product1', // ❌ fake foreign key, will violate db constraints
unitAmount: 100,
}
product = {
organizationId: 'org1', // ❌ fake foreign key
name: 'tester',
}
})
// ❌ ambiguous
it('should correctly handle proper inputs', async () => {
// ❌ dynamic import, just gross
const { myDatabaseMethod } = await import('@/db/myDatabaseMethod')
const result = await db.transaction((tx) => {
return myDatabaseMethod({ price, organization, product }, tx)
})
expect(result).toBeDefined()
})
})
A strict enough linter will catch any, but what about all the other glaring issues? They're based on common patterns found in the code that AI was trained on. But these patterns are problematic for our specific codebase:
- we normally test against DB state, and avoid mocking code as much as possible
- we use test names as a way of documenting correct behavior
Codebase-specific idioms were much harder to enforce with AI agents at the beginning of this year than they are now. Today, we use a mix of:
- Saved prompts, like the one we use to guide the generation of test code, provide examples of good code and explicit instructions of what to do and what to avoid.
- Code review agents with custom rules. Our favorite is cubic.dev, but we've recently added Coderabbit. Multiple review agents seem to help cover blindspots.

Layer 3: Logic + Runtime Bugs
Let's say you've mostly figured out how to get AI to write 1) syntactically correct code that 2) adheres to the idioms of your language, frameworks, and codebase. And the stuff that you miss while you back-and-forth with Cursor, the AI coding agents catch in PR review.
How do you prevent AI from authoring bugs?
The core problem from here on out is one of cost asymmetry: the cost of writing a single line of code has plummeted to ~zero. But the cost of maintaining that code hasn't gone down. In fact, as the rate of new code grows, the cost of maintaining subpar old code may actually go up.
That's because any code you commit will have to compose well with a much larger volume of future code. It will need to be legible to a much larger number of future beings. The majority of these future beings will be ephemeral demons trapped in GPU clusters whose conscious existence will not span much longer than a podcast.
How do we address this?
First: test coverage today is insanely more valuable. So GET REALLY GOOD AT WRITING LOTS OF TESTS. When I tell people that about 70% of Flowglad's codebase is just test coverage, people often respond with "of course, you're in payments where there's zero fault tolerance." They're right, but that's not actually why we are so maniacal about tests. In a sense, the causal arrows are probably flipped: we're building in payments because we are maniacal about test coverage.
You should form strong opinions about writing tests. You should write detailed base prompts to describe your ideal test suite. We've found that it helped to save at least 3 - 4 separate prompts to write test suites quickly. This seemed obvious to us but when I shared it at a dinner with devtool founders I was surprised to find how few of them were doing it:
- A prompt just to enumerate the test cases, so that you can review the cases for completeness (or pass the proposed test cases to another agent to review) (example)
- A prompt to write out the stubbed test code. Helpful for large test suites where the agent might get context overwhelm (example)
- A prompt to write the code that sets up the test cases (
beforeEachin JS test runners; example) - A prompt that implements the stubbed-out tests (example)
You should also write helper functions to do the most common tasks required to set up your test cases. Things like setting up tenants (if SaaS) or getting your database into a specific state.
You should also be meticulous, or build AI review scaffolding, to scale the following conventions:
- articulating detailed test names that describe exactly what's expected in a given scenario
- making sure your test cases are peppered with comments to explain what's going on
- enforcing detailed assertions. consider
.toBeDefined()to be an anti-pattern. Demand more precise enforcement
These are places where you can use the zero-cost of the marginal line of code to your advantage. It's cheap to be a perfectionist here. AI review bots + a few saved prompts can get you better test code in a few seconds. The result is that your business logic will have a more detailed spec for its correctness.
Second: move as much of the problem as possible from logic to types. Zod, and similar parser-validator libraries, are fantastic for this. They create cinch points in your code where, if you get past a schema validator, you know that a certain set of invariants holds true. These invariants can then be encoded in the type system.
const productCheckoutSessionCookieNameParamsSchema = z.object({
type: z.literal('product'),
productId: z.string(),
})
const purchaseCheckoutSessionCookieNameParamsSchema = z.object({
type: z.literal('purchase'),
purchaseId: z.string(),
})
const invoiceCheckoutSessionCookieNameParamsSchema = z.object({
type: z.literal('invoice'),
invoiceId: z.string(),
})
/**
* SUBTLE CODE ALERT:
* The order of z.union matters here!
*
* We want to prioritize the purchase id over the price id,
* so that we can delete the purchase session cookie when the purchase is confirmed.
* z.union is like "or" in natural language:
* If you pass it an object with both a purchaseId and a priceId,
* it will choose the purchaseId and OMIT the priceId.
*
* We actually want this because open purchases are more strict versions than prices
*/
export const checkoutSessionCookieNameParamsSchema =
z.discriminatedUnion('type', [
purchaseCheckoutSessionCookieNameParamsSchema,
productCheckoutSessionCookieNameParamsSchema,
invoiceCheckoutSessionCookieNameParamsSchema,
])
export const setCheckoutSessionCookieParamsSchema = idInputSchema.and(
checkoutSessionCookieNameParamsSchema
)
export type ProductCheckoutSessionCookieNameParams = z.infer<
typeof productCheckoutSessionCookieNameParamsSchema
>
export type PurchaseCheckoutSessionCookieNameParams = z.infer<
typeof purchaseCheckoutSessionCookieNameParamsSchema
>
export type CheckoutSessionCookieNameParams = z.infer<
typeof checkoutSessionCookieNameParamsSchema
>
const checkoutSessionName = (
params: CheckoutSessionCookieNameParams
) => {
const base = 'checkout-session-id-'
switch (params.type) {
case CheckoutSessionType.Product:
return base + params.productId
case CheckoutSessionType.Purchase:
return base + params.purchaseId
case CheckoutSessionType.Invoice:
return base + params.invoiceId
default:
// we know this case will never be hit
throw new Error('Invalid purchase session type: ' + params.type)
}
}
Third: invest in CI/CD. Github actions are amazing. You should require your entire test suite to pass before you can merge into main. And with AI, they are a breeze to set up.
Fourth: this may be a bit more domain-specific, but aim to make your logic as atomic as possible. Database transactions are great for this. It will require some performance engineering to scale this but it's worth setting up the norm early that all your DB operations be atomic. The net result, when combined with parsers that will throw runtime errors, is that you can scale type correctness into data integrity. At the extreme, no data would leave or enter your database without passing through a parser first. Code paths that enforce this level of correctness will never read or write data from your database that is not of a validated, known shape. This is a massive unlock. But it requires up-front commitment.
Layer 4: Design Decisions
As the pace of software development speeds up, and as agents become more capable of executing on longer running tasks, it's inevitable that they will creep into the territory of making design decisions. This is where AI slop becomes most pernicious. If you follow all the above conventions, you write syntactically correct code that passes lint, adheres to your local idioms, and even has good test coverage.
But what if the agent subtly misunderstands what you're trying to do? Or it works to only solve the problem as you prompted it, rather than in a deeper sense? How do you fix this? You need to do lots of back and forth with the agent. It keeps getting off track because its context window is loaded up with a bunch of previous iterations on the problem. You get dejected, wondering if it would have been faster to write it out by hand.
This is where things get really interesting. Stronger models with longer context windows will help, but they definitely won't solve this problem. The problem isn't one of agent capabilities. The problem is one of alignment and shared understanding.
You need to impart your understanding of the problem to the agent. Your existing code is a great jump-off point. But what if you want to update your code? Can you explain what's wrong with your current code? What if the problem spans dozens of files, and runs deeper than a syntactic refactor? Can you explain that in the span of a single textarea submission?
Ok, let's say you can. Maybe Superwhisper makes it easier to braindump using voice rather than typing. Do you really think your AI will "one-shot" the fix? Even if it could, would you want a one shot solution?
Remember the problem: a line of code costs zero to write. But today, that same line costs more to maintain than a line written 6 years ago. Because everyone's shipping faster. The code will be built on at a much faster pace. More beings will work on it and read over it and construct its model of the world in their context windows.
You don't need to write all of the code in your codebase. Hell, for many products you don't even really need to read all of the code in your codebase. But you do need to understand your codebase. You are liable for the code you deploy. You are responsible for making sure it doesn't crash. You are responsible for making sure it doesn't corrupt your customers' data. You are responsible for maintaining your shipping velocity.
And it really doesn't matter how AI-pilled you are: any engineer knows that you can't extend or maintain poorly designed code. Bad understanding produces badly designed primitives, and bad primitives compose poorly. Every codebase eventually becomes a tower of abstractions. Bad understanding, iterated enough, will compound to produce a Tower of Pisa.

If you are naively, imperatively prompting your coding agent to ship incremental features you are building a more slanted tower, more quickly. Your agents write code way faster than you can read it. And with an input barely longer than a tweet, you can get a multi-thousand line PR.
You have to comb through it to see what's going wrong. Or you have to interrupt it to correct it. Now you're knee deep in garbage code, losing patience while your agent loses space in its context window. Both you and the agent are getting overloaded and overwhelmed. Here's what the cycle of suffering looks like:
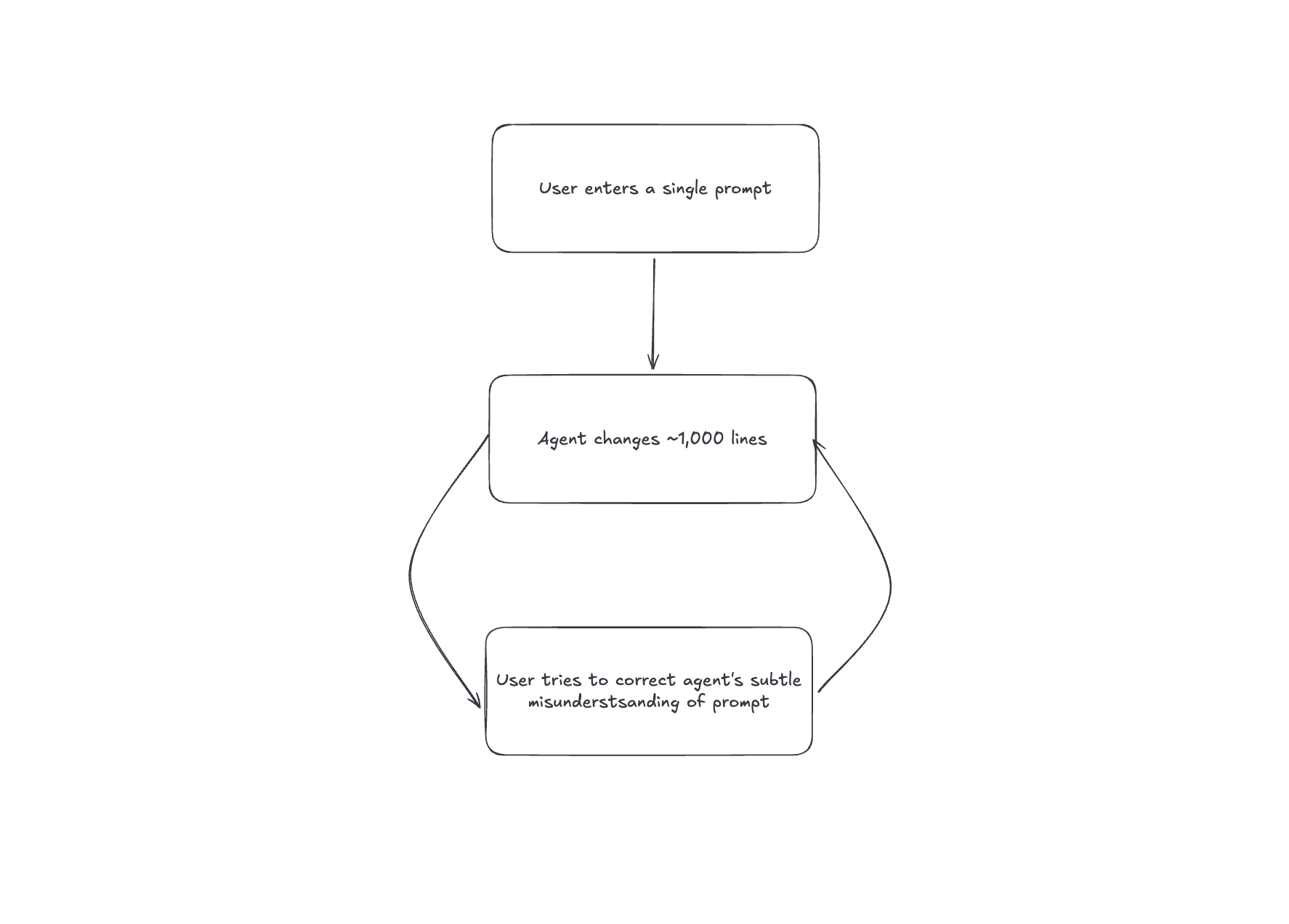
I ran into this problem throughout the year and felt it was awful. But I was too AI-coding pilled to think the problem was with the models, or the whole enterprise of coding with AI. I believe it was a problem with process.
It's clear just a few years in that AI is to coding what the combine harvester was to agriculture. It's an explosive productivity unlock. But to fully realize the gains, we need to retool all of our productive workflows around this new process.
What if instead of diving right into asking for code, we first made a detailed document—we'll call it a gameplan — that memorializes the changes we need to make, PR by PR, to implement a feature? What if instead of reworking code changes in medias res, we could rework a gameplan instead? What if instead of reviewing a massive 3,000 line PR — or 8 — we could instead review a single ~1,000 markdown file describing 8 PRs worth of work? Here's what that would look like:

We now not only get more code, but better code. Not only because the code has more test coverage, or adheres to patterns better. But because AI can help us reason better about the work to be done. The result:
- better design decisions
- less time wasted on rework
- fewer 11th hour surprises caught in PR review
- less time wasted on designing by implementing
- faster review of the resulting code, because you already understand the approach
This means you can execute faster on more complex features. That's awesome! But wait, there's more…
IT SCALES!
Why? Because better designed code is easier to maintain. It's easier to extend well-designed code. It's easier to write tests for well designed code. And it's much easier to comprehensively understand 900 lines of markdown than it is to fully comprehend the 9,000 lines of diff it will produce.
Layer 5: Multiplayer Understanding
Ok, so now we've got scaffolding in place for AI to write syntactically correct, idiomatic, well tested code. And we've figured out how to scale it to large, complex features. Until now we've only described how AI can make a single engineer more productive.
How does it work when they're on a team of engineers? Every engineer now has 5-10x the output that they had in 2019. How do you keep up with all of it? The answer is that you have teammates focus their efforts on reviewing each others' gameplans.
Gameplans prime teammates for what changes are coming up, and greatly reduce the coordination required to land PRs.
In short, by being very selectively perfectionist, you can speed up the entire process, improve the final outcome, and avoid much of the drag that builds up as your codebase grows more and more complex.

Layer 6: Understanding Across Time
AI coding is so new that we have not had enough time to see how it will age. We know a lot already about what methods don't work to produce gracefully aging code. But for AI code intended to live for a long time, it's not fully obvious what patterns produce code that will age well. We know that anything that produces slop at any of the layers discussed above will not age well. But beyond that, the only way to find out is time.
Here's what we've seen so far at Flowglad: one year in, most of the AI-generated code in the Flowglad codebase has aged very gracefully. But that code wasn't naively prompted. It was prompted with a very clear separation of concerns. It was prompted to follow very specific patterns that we meticulously crafted. And while it took a lot of effort, it ultimately sped us up. It slowed down the calcification of our code. And most importantly, it effectively eliminated slop without requiring us to be pedantic or perfectionistic in our code review.
That, to me, is the biggest unlock of coding with AI. You can now produce not just more code, but higher quality code, and faster. You just need to think a bit about your process.